Graph database是近年兴起的NoSQL存储模型(graph, key-value, column, and document)中的一种实现数据库,代表产品是Neo4j、Titan,它的理论基础是图论/Graph theory,一个数学分支,主要研究顶点和边组成的图形的数学理论和方法,它的起源也比较有意思,这部分本文不谈,感兴趣的同学可以去Google研究一下。
Titan:下一代分布式图数据库
Titan是一个由Aurelius维护的开源协议为Apache 2.0的分布式图形数据库。
Storm与Kafka集成开发
项目源码在这里storm-kafka,里面包括了简单说明和测试过程,照着做就可以了,下面简单介绍一下。

Caused by: java.io.NotSerializableException: kafka.javaapi.producer.Producer
我们现在的架构使用Kafka作为消息的入口,数据全部发送到Kafka中,然后用Storm的Topology写一个spout去订阅Kafka的消息,执行提交Topology:
Java-WebSocket
本文涉及到几个概念后面细说,Websocket协议、socket.io、Java-WebSocket,核心都是围绕Websocket,最后重点讲解在Java端实现Websocket的访问。
Storm Spouts Lifecycle
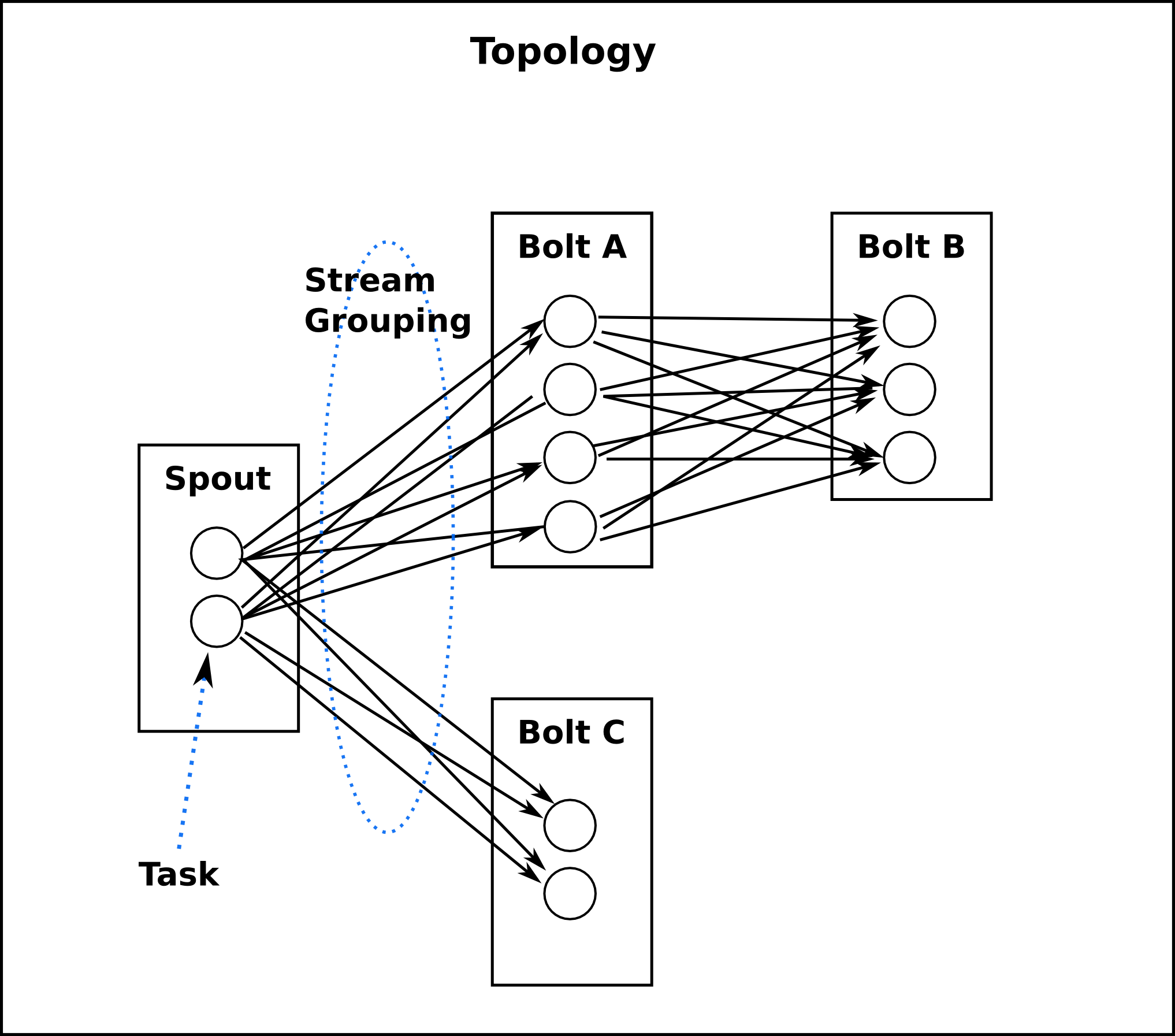
Spouts是Storm中的Topology对应的消息生产者,消息将从Spouts发出,消息的单位是tuple,本文讲解Spouts核心方法以及Spouts方法的生命周期。相关接口方法看这里:ISpout。Spouts在Storm中的位置可以参考下图:
Kafka vs MQ vs JMS
Kafka的介绍参加这篇文章:Kafka Introduction,本文将Kafka、MQ、JMS这几个概念重新梳理一下,当然它们之间是有包含的关系,还有已经有了那么多的MQ产品,为什么LinkedIn还要开发Kafka呢?
Computational Advertising
最近在学习计算广告学,一个互联网广告行业催生出来的新兴学科,斯坦福大学已经推出了计算广告学的课程,本文下面有公开课的链接。
Open Datasource
大数据时代没有数据是玩不转的,真正拥有大数据的公司少之又少,更何况是个人开发者呢。数据有很多,最接近用户诉求、最能够精准定位用户需求的数据是最具有商业价值的,像搜索、电商、社交,而拥有这些数据的公司:Google、Facebook、百度、阿里巴巴、亚马逊等,它们首先会通过广告、增值服务等形式来将数据变现,肯定不会将数据开放出来,而且未来数据会越来越成为一个公司的核心竞争力。
对于大数据研究人员或者创业者,我们有哪些数据可以使用呢?我简单整理了一下。
S3cmd Configure
s3cmd是AWS S3的命令行工具,可以用来下载、上传、同步文件,还可以配置权限。