Kafka是Linkedin于2010开源的消息系统,现在已经放到Apache的项目中了,主页是:http://kafka.apache.org/%E3%80%82 Kafka是一个高吞吐量分布式的消息系统(publish-subscribe),它有如下这些特点:
- 高性能:单个Kafka broker节点就可以处理来自数千个客户端数百MB的消息读取和写入。
- 可扩展:集群设计可以保证弹性扩展而不停机
- 持久化:消息被持久化到磁盘上,并且在集群内会有复制备份,所以不会有数据丢失。并且每一个broker可以处理TB级的消息而不影响性能
- 分布式:分布式集群设计保证了系统的健壮性和容错性
Kafka的部署结构图
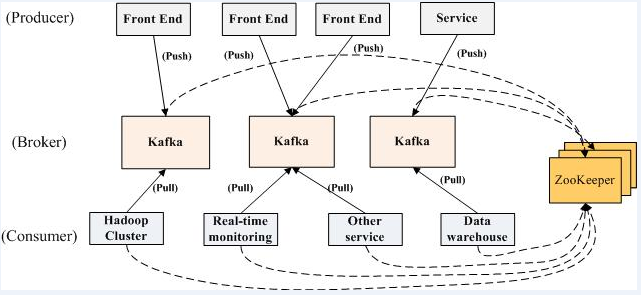
为什么要用Kafka
- 统一消息入口
Storm流数据平台需要处理的数据多种多样,如果直接用Storm来接入,会需要写很多的接口,这样必然不是最佳的解决方案,加了一层Kafka之后,Storm只需要处理来自Kafka的数据,由Kafka对接数据源。 - 消息持久化
直接用Storm或者其它MQ会发生数据丢失的可能,而Kafka是把数据持久化到磁盘上面而且会有复制备份,所以不会发生数据丢失。 - 支持分布式
支持分布式保证了架构的健壮性、弹性扩展和容错。
Kafka在数据平台中的位置如图:
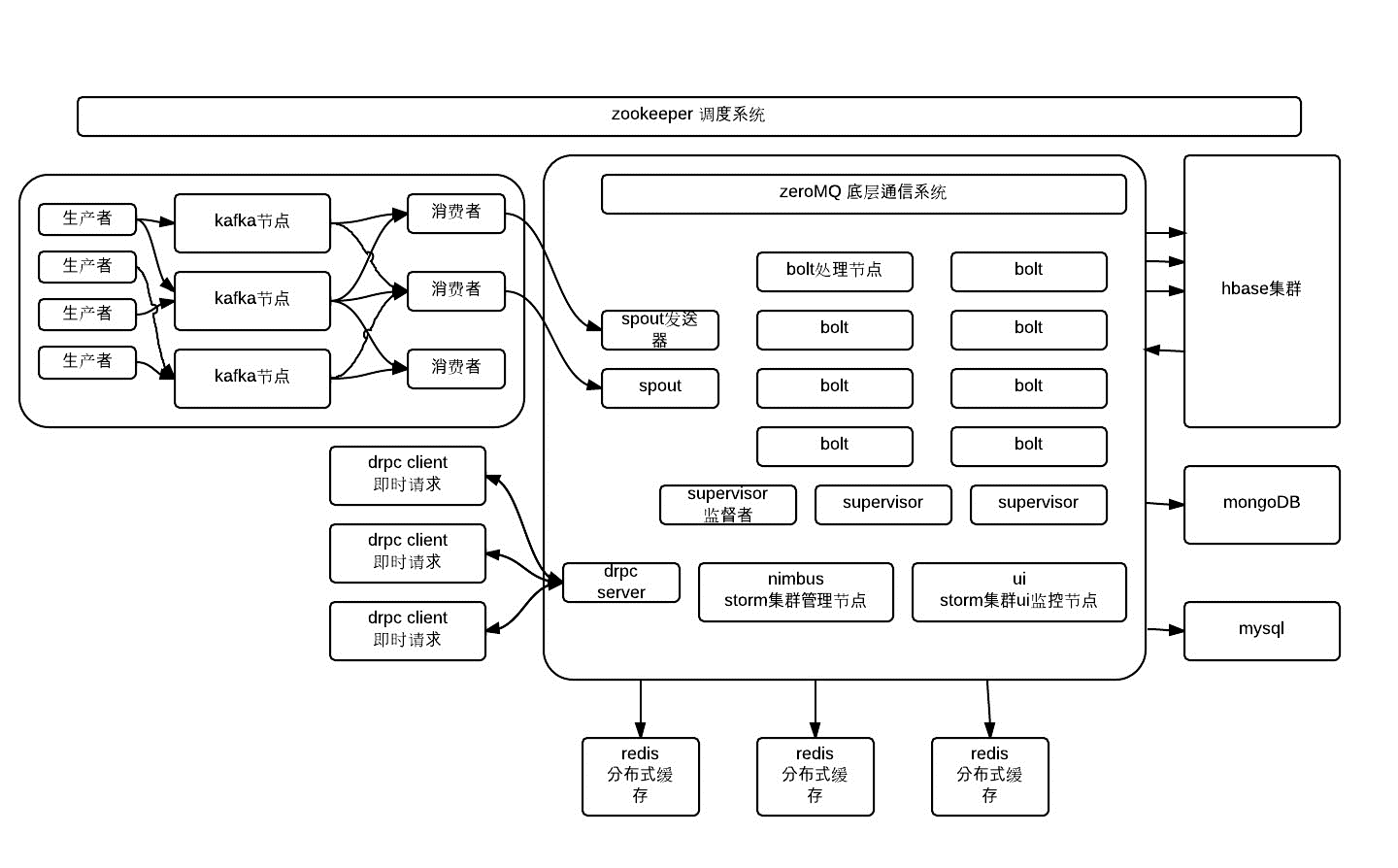
Kafka作为消息中间件,为Storm提供数据来源。
Zookeeper为Kafka、Storm、HBase提供分布式协调服务,所以单独部署,不用HBase自带的Zookeeper。
HBase作为Storm的持久化层,也作为Titan的数据存储层。