Mahout 是一个开源的Java实现的可伸缩的机器学习库,它实现了常见的聚类和推荐等机器学习算法,并且可运行在 Hadoop 分布式平台处理上PB的数据,Mahout 社区和文档非常丰富,是目前搭建推荐系统或者其它算法平台的首选方案。
目录
- 一、前言
- 1、Mahout 介绍
- 2、Mahout 最新动态 – Goodbye MapReduce
- 3、算法介绍
- 二、Mahout 架构介绍
- 三、Mahout Startup
一、前言
1、Mahout介绍
Mahout 是 Apache Software Foundation (ASF) 开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在 Apache 在许可下免费使用,Mahout项目是由 Apache Lucene社区中对机器学习感兴趣的一些成员发起的,他们希望建立一个可靠、文档翔实、可伸缩的项目,在其中实现一些常见的用于聚类和分类的机器学习算法,该社区最初基于 Ngetal. 的文章 “Map-Reduce for Machine Learning on Multicore”,但此后在发展中又并入了更多广泛的机器学习方法,包括Collaborative Filtering(CF),Dimensionality Reduction,Topic Models等。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。在Mahout的Recommendation类算法中,主要有User-Based CF,Item-Based CF,ALS,ALS on Implicit Feedback,Weighted MF,SVD++,Parallel SGD等。
2、Mahout 最新动态 – Goodbye MapReduce
在今年4月25日,Mahout官方发布了一则新闻:
25 April 2014 - Goodbye MapReduce
The Mahout community decided to move its codebase onto modern data processing systems that offer a richer programming model and more efficient execution than Hadoop MapReduce. Mahout will therefore reject new MapReduce algorithm implementations from now on. We will however keep our widely used MapReduce algorithms in the codebase and maintain them.
We are building our future implementations on top of a DSL for linear algebraic operations which has been developed over the last months. Programs written in this DSL are automatically optimized and executed in parallel on Apache Spark.
Furthermore, there is an experimental contribution undergoing which aims to integrate the h20 platform into Mahout.
主要的意思是Mahout社区决定放弃MapReduce数据处理模型,而将代码库迁移到处理速度更快更丰富的数据处理模型,但是原来实现MapReduce算法还可用且继续维护。过去几个月Mahout团队正在开发DSL for linear algebraic operations,使用DSL模型编写的代码可以在Spark平台中自动优化和并行执行,可以看出Mahout开始向Spark靠近,后面会将它的算法实现更加适应于Spark平台,来达到性能的大幅提升,因为我们知道Spark是基于内存,它本身处理数据的性能要远高于MapReduce,关于这个更多可以参考Mahout-Jira,这里也有关于DSL的解释,我现在还没有太理解清楚:
The second set of DSL is for (looking identically to in-core set of operators) is for distributed stuff.
(on diagram those two are not visually separated other than there's just part of it over in-core
and part of it over distributed optimizer).
3、算法介绍
Mahout实现了大多数常用的算法,详细列表可以看Mahout-algorithms,它共有3种实现,第一种是单机的(single machine),受限于单机的性能处理较小量级的数据,第二种分布式实现(MapReduce),算法可以运行在Hadoop分布式平台中,性能可以横向扩展,可以处理上PB的数据,第三种是Spark实现,算法可以跑在Spark平台上,这个也是上面提到的,Mahout开始转向Spark平台,后面更多算法会迁移到Spark平台。下面介绍几个常用的算法。
3.1、Recommendation
推荐,给用户找到他想要的物品是目前互联网平台用的最多的算法,包括电商网站的商品推荐,社交平台的好友推荐,内容平台类似豆瓣的电影、图书推荐等等,被用的最多的是协同过滤算法(Collaborative Filtering-based Recommendation),就是物品或者用户的相似度找到同类物品或用户来进行推荐,协同过滤算法又有三个分支:
- 基于用户的推荐(User-based Recommendation):发现与当前用户口味偏好相近的用户进行推荐,就是电商网站的:购买了此物品的用户还购买了哪些物品推荐
- 基于项目的推荐(Item-based Recommendation):发现与当前用户购买物品相似的物品进行推荐,就是电商网站的:组合购买或者是你还可以购买哪些物品
- 和基于模型的推荐(Model-based Recommendation):这个通常是基于历史数据来训练一个模型来进行推荐
3.2、Clustering
聚类,是把一个数据对象划分成子集的过程,每个子集是一个簇(cluster),簇内的对象彼此相似,但与其它簇中的对象不相似,它通常用于商务管理中的客户分类,为不同的客户群制定不同的营销策略,还有离群点监测,就是那些远离任何簇的值,常用在金融交易中的信用卡欺诈校验。聚类作为统计学的一个分支,已经被广泛研究多年,主要集中在基于距离的聚类分析,基于K-均值(K-means)、K-中性点(K-medoids)。
二、Mahout 架构介绍
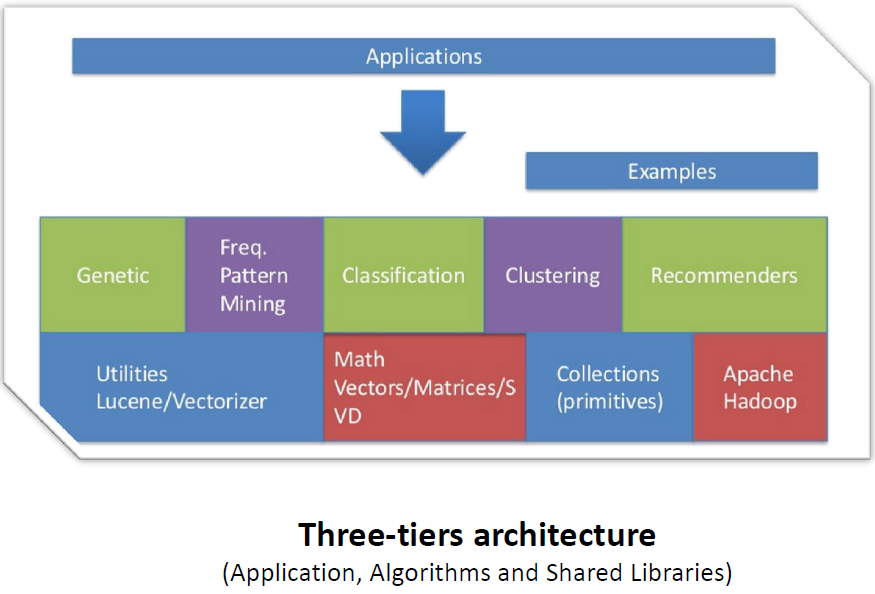
这个Mahout整个业务架构图,最下面是Mahout的底层数学模型库和数据存储,Mahout可以从HDFS中读取数据,中间是它的算法实现,上面是业务层。
三、Mahout Startup
这里构建基于Mahout的maven项目,和一个算法实例:User-based Recommendation。
1、POM文件加入依赖
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.7</version>
</dependency>
2、准备源文件
1,3
1,4
2,44
2,46
3,3
3,5
3,6
4,3
4,5
4,11
4,44
5,1
5,2
5,4
3、示例代码
package com.find.mahout.recommend;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.List;
import org.apache.commons.cli2.OptionException;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.recommender.CachingRecommender;
import org.apache.mahout.cf.taste.impl.recommender.slopeone.SlopeOneRecommender;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
public class UserCFMahout {
public static void main(String[] args) throws FileNotFoundException, TasteException, IOException, OptionException {
// 创建DataModel slopeOne
File ratingsFile = new File("E:\\cy-bigdata-project\\mahout-example\\src\\main\\resources\\datafile\\slopeOne.csv");
DataModel model = new FileDataModel(ratingsFile);
// 创建Recommender,使用SlopeOneRecommender
CachingRecommender cachingRecommender = new CachingRecommender(new SlopeOneRecommender(model));
// for all users
for (LongPrimitiveIterator it = model.getUserIDs(); it.hasNext();) {
long userId = it.nextLong();
// get the recommendations for the user
List<RecommendedItem> recommendations = cachingRecommender.recommend(userId, 10);
// if empty write something
if (recommendations.size() == 0) {
System.out.print("User ");
System.out.print(userId);
System.out.println(": no recommendations");
}
// print the list of recommendations for each
for (RecommendedItem recommendedItem : recommendations) {
System.out.print("User ");
System.out.print(userId);
System.out.print(": ");
System.out.println(recommendedItem);
}
}
}
}
4、测试结果
User 1: RecommendedItem[item:5, value:1.0]
User 2: RecommendedItem[item:5, value:1.0]
User 2: RecommendedItem[item:3, value:1.0]
User 3: no recommendations
User 4: no recommendations
User 5: RecommendedItem[item:5, value:1.0]
User 5: RecommendedItem[item:3, value:1.0]
更多例子请参考这个项目:https://github.com/findhy/mahout-example