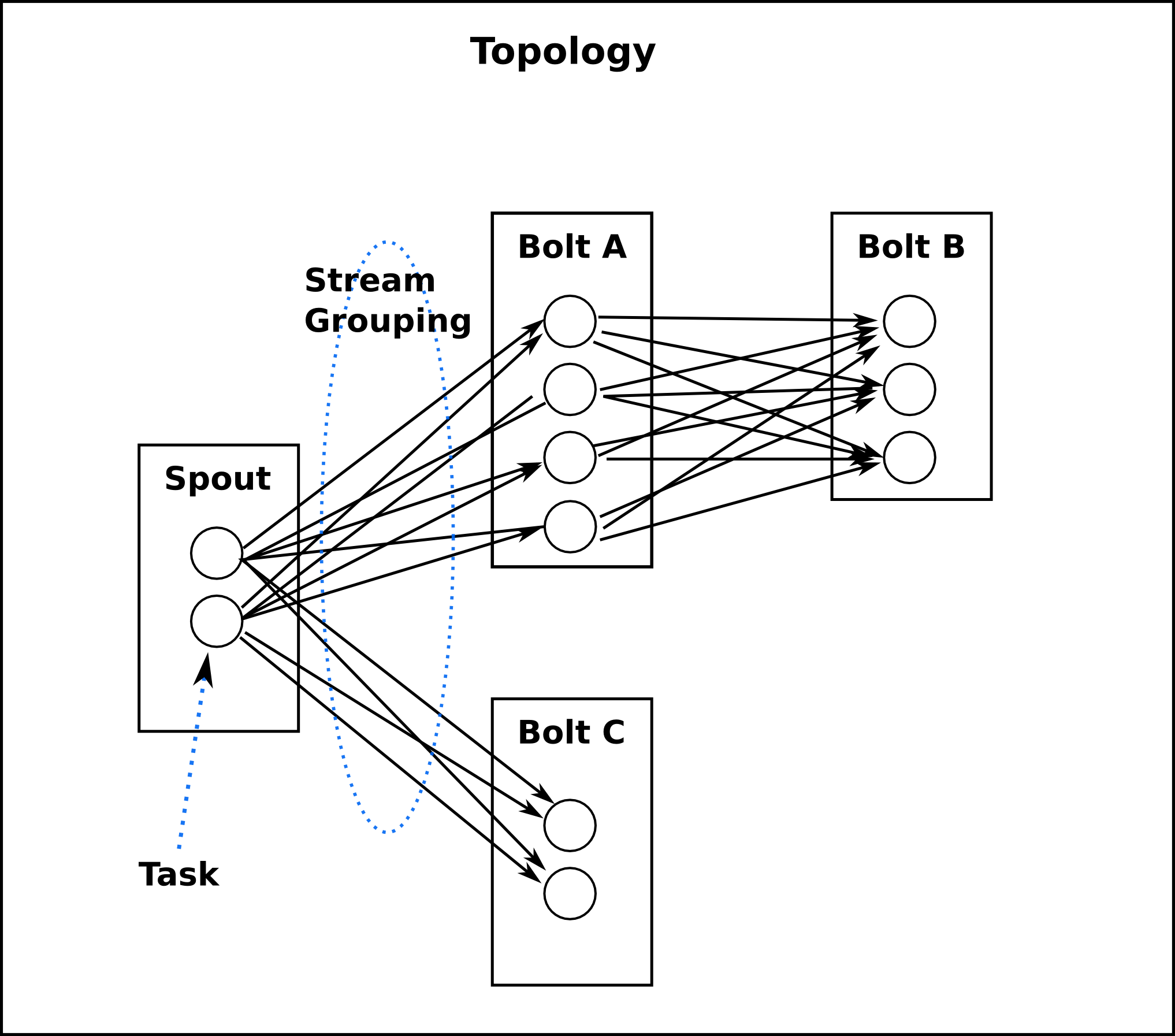
Spouts是Storm中的Topology对应的消息生产者,消息将从Spouts发出,消息的单位是tuple,本文讲解Spouts核心方法以及Spouts方法的生命周期。相关接口方法看这里:ISpout。Spouts在Storm中的位置可以参考下图:
1.初始化
当我们自定义一个Spouts的时候,继承BaseRichSpout类,代码是这样的:
public class TestWordSpout extends BaseRichSpout{
public static Logger LOG = LoggerFactory.getLogger(TestWordSpout.class);
SpoutOutputCollector _collector;
@Override
public void open(Map conf, TopologyContext context,SpoutOutputCollector collector) {
_collector = collector;
}
@Override
public void nextTuple() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
BaseRichSpout是Storm提供的一个抽象类,代码如下:
/*
* To change this template, choose Tools | Templates
* and open the template in the editor.
*/
package backtype.storm.topology.base;
import backtype.storm.topology.IRichSpout;
/**
*
* @author nathan
*/
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public void ack(Object msgId) {
}
@Override
public void fail(Object msgId) {
}
}
可以看到BaseRichSpout没有做任何事情就是实现了接口的方法,没有任何具体实现,这样子类不用显式实现方法了,它继承了BaseComponent,实现了接口IRichSpout,而IRichSpout接口是继承自ISpout, IComponent这两个接口,BaseComponent类如下:
package backtype.storm.topology.base;
import backtype.storm.topology.IComponent;
import java.util.Map;
public abstract class BaseComponent implements IComponent {
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
可以看到BaseComponent只是实现了接口的方法getComponentConfiguration()返回null。
下面来看下ISpout, IComponent这两个接口
package backtype.storm.topology;
import java.io.Serializable;
import java.util.Map;
public interface IComponent extends Serializable {
void declareOutputFields(OutputFieldsDeclarer declarer);
Map<String, Object> getComponentConfiguration();
}
package backtype.storm.spout;
import backtype.storm.task.TopologyContext;
import java.util.Map;
import java.io.Serializable;
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void activate();
void deactivate();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
上面把javadoc都去掉,如果要看的话直接看源码,或者到这里看:http://storm.incubator.apache.org/apidocs 到这里基本可以看到核心的接口方法主要在IComponent和ISpou这两个接口中定义,下面详细讲解。
2.IComponent接口方法详解
IComponent接口是topology中所有组件的顶层接口,包括Spouts、Bolts,它定义了两个核心的公共方法:
/**
* 该方法是用来定义topology中的spout或者bolt的ID,而且该ID在同是spouts或者bolts内部不能重复,但是spouts和bolts之间的ID可以重复
* 如果没有显示指定该值,则默认使用Utils.DEFAULT_STREAM_ID这个值
* 这里可以参考Storm源码TopologyBuilder类里面的validateUnusedId这个方法
*
* 该方法在客户端调用createTopology()方法时被执行,同样参见TopologyBuilder类
*
* 源码:https://github.com/nathanmarz/storm/blob/moved-to-apache/storm-core/src/jvm/backtype/storm/topology/TopologyBuilder.java#L226
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* 该方法可以用来配置组件
*
* Declare configuration specific to this component. Only a subset of the "topology.*" configs can
* be overridden. The component configuration can be further overridden when constructing the
* topology using {@link TopologyBuilder}
*
*/
Map<String, Object> getComponentConfiguration();
3.ISpout接口方法详解
/**
* 该方法在task任务组件在worker里初始化的时候被调用,它提供了spout的执行环境
* Called when a task for this component is initialized within a worker on the cluster.
* It provides the spout with the environment in which the spout executes.
*
* <p>This includes the:</p>
*
* @param conf The Storm configuration for this spout. This is the configuration
* provided to the topology merged in with cluster configuration on this machine.
* @param context This object can be used to get information about this task's place
* within the topology, including the task id and component id of this task, input
* and output information, etc.
*
* @param collector The collector is used to emit tuples from this spout.
* Tuples can be emitted at any time, including the open and close methods.
* The collector is thread-safe and should be saved as an instance variable of this spout object.
*/
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
/**
* Spout停掉的时候会调用此方法
*
* Called when an ISpout is going to be shutdown. There is no guarentee that close
* will be called, because the supervisor kill -9's worker processes on the cluster.
*
* <p>The one context where close is guaranteed to be called is a topology is
* killed when running Storm in local mode.</p>
*/
void close();
/**
* spout由deactivated模式转为activated模式时被调用
*
* Called when a spout has been activated out of a deactivated mode.
* nextTuple will be called on this spout soon. A spout can become activated
* after having been deactivated when the topology is manipulated using the
* `storm` client.
*/
void activate();
/**
* spout被deactivated的时候调用,并且当spout被deactivated时,nextTuple就不会被调用了
*
* Called when a spout has been deactivated. nextTuple will not be called while
* a spout is deactivated. The spout may or may not be reactivated in the future.
*/
void deactivate();
/**
* spout发射Tuple时被调用,该方法必须是非阻塞的(non-blocking),这样如果Spout没有tuples可以发射了,
* 这个方法也会返回,nextTuple, ack, and fail这几个方法在同一个spout task同一个线程里面是会被循环调用的,
* 当没有tuples可以发射了,应该让线程sleep一段时间
* 这样就不会占用太多的CPU资源了
*
* When this method is called, Storm is requesting that the Spout emit tuples to the
* output collector. This method should be non-blocking, so if the Spout has no tuples
* to emit, this method should return. nextTuple, ack, and fail are all called in a tight
* loop in a single thread in the spout task. When there are no tuples to emit, it is courteous
* to have nextTuple sleep for a short amount of time (like a single millisecond)
* so as not to waste too much CPU.
*/
void nextTuple();
/**
* Storm可以保证spout发射出去的tuples必须被处理了,msgId就是就是发射的消息的ID
* 当tuples被处理完了之后,该方法会被调用,并且将它从队列中去掉防止被反复处理
*
* Storm has determined that the tuple emitted by this spout with the msgId identifier
* has been fully processed. Typically, an implementation of this method will take that
* message off the queue and prevent it from being replayed.
*/
void ack(Object msgId);
/**
* 如果msgId对应的tuples处理失败,该方法会被调用,通常的实现会将tuples重新放回队列,让它多一段时间可以被处理
* 上面两个方法ack和fail是Storm保证数据一定被处理和避免重复处理的机制,
* 参数msgId就是每次发射tuples的时候spout提供的一个
* message-id,后面可以通过这个message-id来追踪这个tuple
*
* The tuple emitted by this spout with the msgId identifier has failed to be
* fully processed. Typically, an implementation of this method will put that
* message back on the queue to be replayed at a later time.
*/
void fail(Object msgId);
4.总结
- 客户端提交Topology的时候,首先调用declareOutputFields(…)方法,指定spout和bolt的ID,如果没有实现该方法则默认为Utils.DEFAULT_STREAM_ID
- 然后Storm会在worker进程内初始化task的运行环境,再调用open(…)方法,传回SpoutOutputCollector对象,后面我们后可以SpoutOutputCollector来发射tuples
- 然后Storm就会反复调用spout的nextTuple方法获取下一个tuple,如果任务处理成功了就调用ack方法,如果任务处理失败就调用fail方法
- 并且Spout发射tuple会提供一个message-id,后面我们通过这个message-id来追踪这个tuple,ack和fail接受的参数就是该message-id
- 一个tuple可能会产生多个tuple,最终形成一个tuple树,Storm会跟踪整个tuple树,如果其中一个叶子tuple失败,那么整个tuple树会重新被处理
- 值得注意的一点是,storm调用ack或者fail的task始终是产生这个tuple的那个task。所以如果一个spout被分成很多个task来执行, 消息执行的成功失败与否始终会通知最开始发出tuple的那个task
- 每个你处理的tuple, 必须被ack或者fail。因为storm追踪每个tuple要占用内存。所以如果你不ack/fail每一个tuple, 那么最终你会看到OutOfMemory错误。
本文参考:
Storm如何保证消息不丢失
storm-spouts
storm-javadocs
storm的一些关键概念
storm入门