使用场景
Storm可以通过插件运行在Hadoop YARN平台上,由YARN统一调度实现资源的共享。Storm可以使用任何语言来写topologies。
下面五个特性保证了Storm实时处理的能力:
- Fast – 快,每个节点每秒可以处理百万个100字节的消息
- Scalable – 可扩展,这没得说
- Fault-tolerant – 容错,如果workers进程死掉,Storm会自动重启。如果一个节点死掉,会在其它节点上重启workers进程
- Reliable – 可靠性,Storm确保每个单元数据(tuple)会被处理最少一次,仅仅当消息处理失败才会发生通知
- Easy to operate – 标准的配置适应于生产环境,一旦部署,Storm很容易操作。
Storm架构
一个Storm集群应该包含下面三类节点
- Nimbus Node – master节点,相当于Hadoop集群的JobTracker,负责:Uploads computations for execution(不懂)、在集群中分发代码、负责在集群中启动workers进程、监控计算资源如果需要会重新分配workers进程
- ZooKeeper Nodes – 负责协调Storm集群,当然也可以由YARN平台来管理
- Supervisor Nodes – 通过Zookeeper或者YARN与Nimbus节点通信,根据Nimbus返回的消息来启动和停止workers进程
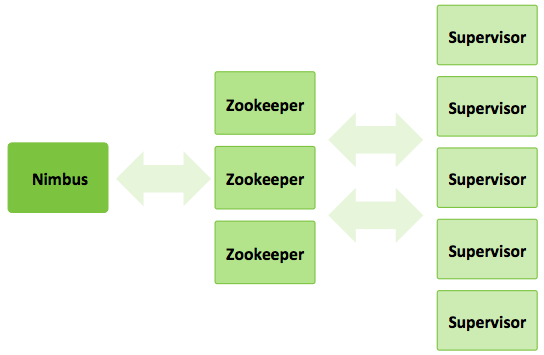
通过下面5个关键点来理解Storm是如何处理数据的:
- Tuples – 元素的有序列表,例如“4-tuple”可能是(7,1,3,7)
- Streams – 一个没有边界的tuples序列
- Spouts – 集群中传输的计算资源(例如 Twitter API)
- Bolts – 处理输入输出流,可以:启动函数、过滤器、统计或合并数据,或访问数据库
- Topologies – 由Spouts和Bolts组成的网络结构
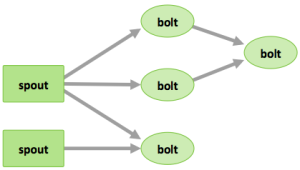
数据由spout输入,由bolt处理,然后存入Hadoop中。
更多请访问这里
可以从这里开始练习。