YARN是Hadoop2.0版本推出的全新数据处理平台。通过YARN,用户可以在Hadoop平台中根据不同的应用场景选择不同的计算框架(MR、TEZ等),而且可以同时处理同一批数据。
YARN的目标
- 伸缩性:不再局限于MapReduce,可以集成其它实时性、流处理等计算模型
- 效率:有效的资源管理和性能预测
- 资源共享:资源共享与合理分配
应用情况
Hadoop2.0加入YARN后与1.0比较,如下图:
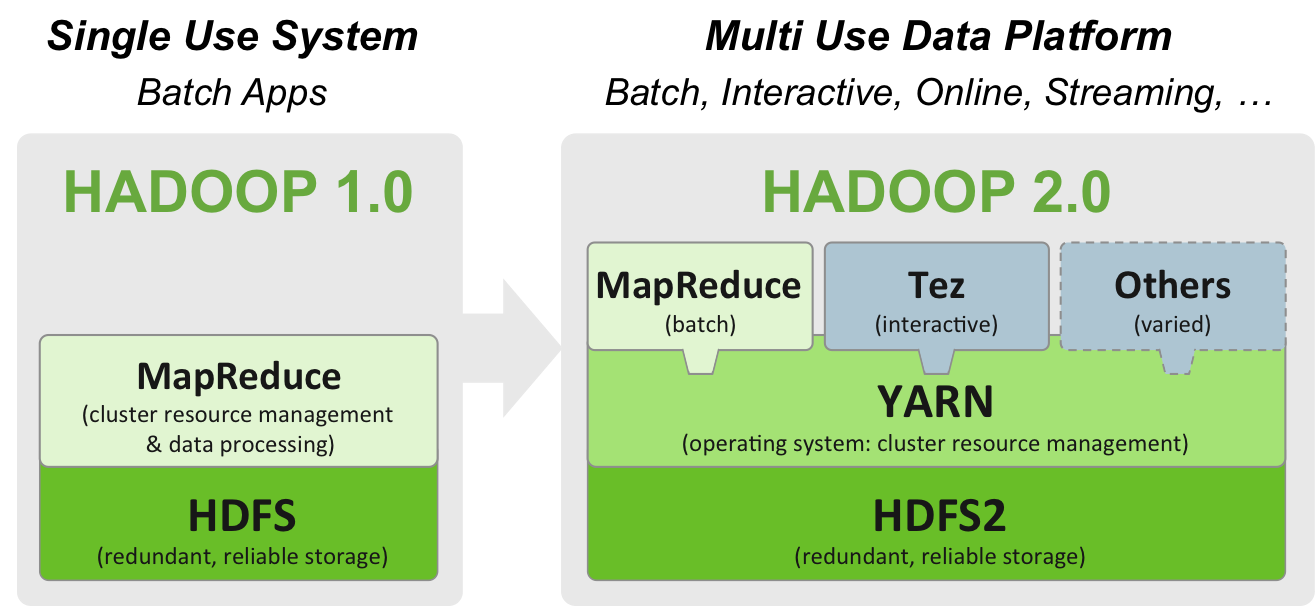
YARN从2012年9月开始在Yahoo!测试,并且从2013年1月开始已经在生产环境部署超过30000个节点,处理数据325PB。最近Microsoft, EBay, Twitter and Xing等商业公司也已经开始基于YARN来开发框架。
伸缩性
YARN将原来的MapReduce抽象为两层,资源管理和计算引擎,资源管理部分相当于Hadoop平台的操作系统,负责资源的分配和协调。并且可以在这个操作系统上面部署多种计算引擎。
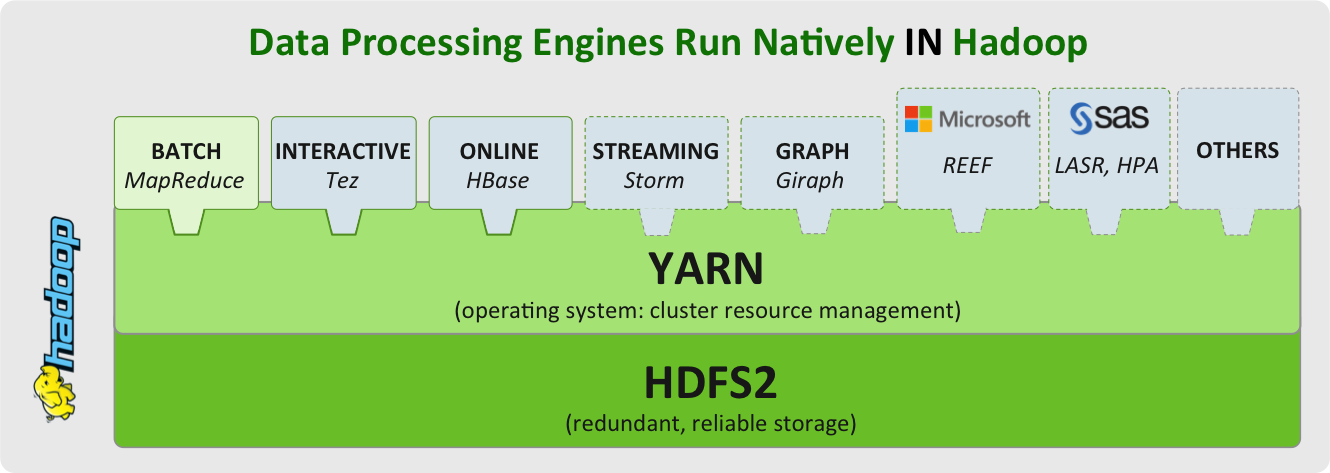
效率&共享
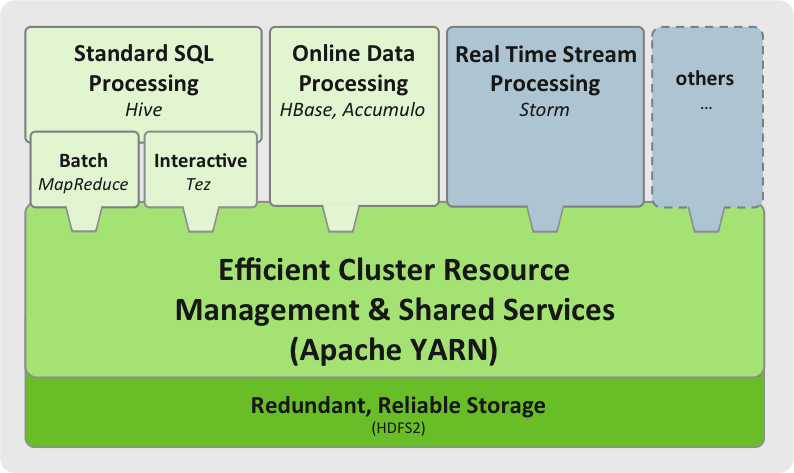
YARN允许在一个集群上运行多个计算引擎,数据和CPU、IO等资源都是共享的,由YARN来协调资源的分配和利用,它有这些特点:
- 资源管理和监控
- 多租户
- 安全
- 高可用
- 灾难恢复
original link:
<a href='http://findhy.github.io/blog/2014/03/20/yarn/'>http://findhy.github.io/blog/2014/03/20/yarn/</a><br/>
written by <a href='http://findhy.github.io'>Findhy</a>
posted at <a href='http://findhy.github.io'>http://findhy.github.io</a>
</p>